Helm方式部署Prometheus+Grafana
部署Prometheus
随着heapster项目停止更新并慢慢被metrics-server取代,集群监控这项任务也将最终转移。prometheus的监控理念、数据结构设计其实相当精简,包括其非常灵活的查询语言;但是对于初学者来说,想要在k8s集群中实践搭建一套相对可用的部署却比较麻烦,由此还产生了不少专门的项目(如:prometheus-operator),本文介绍使用helm chart部署集群的prometheus监控。
helm已成为CNCF独立托管项目,预计会更加流行起来
部署前提
- kubernetes中已安装好helm组件
- kubernetes中已部署好core-dns
部署准备
参考资料(感谢项目组成员的贡献,此篇文档也是参照补充出来的):
https://github.com/gjmzj/kubeasz/blob/master/docs/guide/prometheus.md
相关文件获取:
https://github.com/gjmzj/kubeasz/tree/master/manifests/prometheus
安装目录概览:
#ll /etc/ansible/manifests/prometheus
drwx------ 3 root root 4096 Jun 3 22:42 grafana/
-rw-r----- 1 root root 67875 Jun 4 22:47 grafana-dashboards.yaml
-rw-r----- 1 root root 690 Jun 4 09:34 grafana-settings.yaml
-rw-r----- 1 root root 1105 May 30 16:54 prom-alertrules.yaml
-rw-r----- 1 root root 474 Jun 5 10:04 prom-alertsmanager.yaml
drwx------ 3 root root 4096 Jun 2 21:39 prometheus/
-rw-r----- 1 root root 294 May 30 18:09 prom-settings.yaml
文件说明:
-
目录
prometheus/和grafana/即官方的helm charts,可以使用helm fetch --untar stable/prometheus和helm fetch --untar stable/grafana下载,本安装不会修改任何官方charts里面的内容,这样方便以后跟踪charts版本的更新。 -
prom-settings.yaml:个性化prometheus安装参数,比如禁用PV,禁用pushgateway,设置nodePort等。 -
prom-alertrules.yaml:配置告警规则,后面单独说。 -
prom-alertsmanager.yaml:配置告警邮箱设置,跟你自己的信息修改等。 -
grafana-settings.yaml:个性化grafana安装参数,比如用户名密码,datasources,dashboardProviders等。 -
grafana-dashboards.yaml:预设置dashboard模板文件。
启用持久化存储卷
-
因生产环境一般都是需要持久化存储收集和监控的数据,所以需要启用存储卷,利用我之前已经准备好的glusterfs+heketi方式部署的集群存储,实现动态存储卷,具体请参看我的另一篇《Kubernetes部署Glusterfs+Heketi》部署文档。
-
helm安装prometheus启用持久化存储,需要修改prometheus目录下values.yaml的配置文件中alertmanager&server部分关于持久化存储定义的参数值,相关部分参考如下:
values.yaml
server:
## Prometheus server container name
##
name: server
persistentVolume:
## If true, Prometheus server will create/use a Persistent Volume Claim
## If false, use emptyDir
##
enabled: true
## Prometheus server data Persistent Volume access modes
## Must match those of existing PV or dynamic provisioner
## Ref: http://kubernetes.io/docs/user-guide/persistent-volumes/
##
accessModes:
- ReadWriteOnce
## Prometheus server data Persistent Volume annotations
##
annotations: {}
## Prometheus server data Persistent Volume existing claim name
## Requires server.persistentVolume.enabled: true
## If defined, PVC must be created manually before volume will be bound
existingClaim: ""
## Prometheus server data Persistent Volume mount root path
##
mountPath: /data
## Prometheus server data Persistent Volume size
##
size: 20Gi
## Prometheus server data Persistent Volume Storage Class
## If defined, storageClassName: <storageClass>
## If set to "-", storageClassName: "", which disables dynamic provisioning
## If undefined (the default) or set to null, no storageClassName spec is
## set, choosing the default provisioner. (gp2 on AWS, standard on
## GKE, AWS & OpenStack)
##
storageClass: "glusterfs-storage"
alertmanager:
## If false, alertmanager will not be installed
##
enabled: true
## alertmanager container name
##
name: alertmanager
persistentVolume:
## If true, alertmanager will create/use a Persistent Volume Claim
## If false, use emptyDir
##
enabled: true
## alertmanager data Persistent Volume access modes
## Must match those of existing PV or dynamic provisioner
## Ref: http://kubernetes.io/docs/user-guide/persistent-volumes/
##
accessModes:
- ReadWriteOnce
## alertmanager data Persistent Volume Claim annotations
##
annotations: {}
## alertmanager data Persistent Volume existing claim name
## Requires alertmanager.persistentVolume.enabled: true
## If defined, PVC must be created manually before volume will be bound
existingClaim: ""
## alertmanager data Persistent Volume mount root path
##
mountPath: /data
## alertmanager data Persistent Volume size
##
size: 5Gi
## alertmanager data Persistent Volume Storage Class
## If defined, storageClassName: <storageClass>
## If set to "-", storageClassName: "", which disables dynamic provisioning
## If undefined (the default) or set to null, no storageClassName spec is
## set, choosing the default provisioner. (gp2 on AWS, standard on
## GKE, AWS & OpenStack)
##
# storageClass: "-"
storageClass: "glusterfs-storage"
prom-settings.yaml
alertmanager:
persistentVolume:
enabled: true
service:
type: NodePort
nodePort: 39001
server:
persistentVolume:
enabled: true
service:
type: NodePort
nodePort: 39000
pushgateway:
enabled: true
kubeStateMetrics:
image:
repository: mirrorgooglecontainers/kube-state-metrics
其他一些告警邮箱设置以及配置告警规则和个性化prometheus安装参数一些修改,根据实际情况修改即可。
安装Prometheus
$ source ~/.zshrc
$ cd /etc/ansible/manifests/prometheus
# 安装 prometheus chart,如果你的helm安装没有启用tls证书,请使用helm命令替换以下的helms命令
$ helms install \
--name monitor \
--namespace monitoring \
-f prom-settings.yaml \
-f prom-alertsmanager.yaml \
-f prom-alertrules.yaml \
prometheus
- 安装后信息提示:
NOTES:
The Prometheus server can be accessed via port 80 on the following DNS name from within your cluster:
monitor-prometheus-server.monitoring.svc.cluster.local
Get the Prometheus server URL by running these commands in the same shell:
export NODE_PORT=$(kubectl get --namespace monitoring -o jsonpath="{.spec.ports[0].nodePort}" services monitor-prometheus-server)
export NODE_IP=$(kubectl get nodes --namespace monitoring -o jsonpath="{.items[0].status.addresses[0].address}")
echo http://$NODE_IP:$NODE_PORT
The Prometheus alertmanager can be accessed via port 80 on the following DNS name from within your cluster:
monitor-prometheus-alertmanager.monitoring.svc.cluster.local
Get the Alertmanager URL by running these commands in the same shell:
export NODE_PORT=$(kubectl get --namespace monitoring -o jsonpath="{.spec.ports[0].nodePort}" services monitor-prometheus-alertmanager)
export NODE_IP=$(kubectl get nodes --namespace monitoring -o jsonpath="{.items[0].status.addresses[0].address}")
echo http://$NODE_IP:$NODE_PORT
The Prometheus PushGateway can be accessed via port 9091 on the following DNS name from within your cluster:
monitor-prometheus-pushgateway.monitoring.svc.cluster.local
Get the PushGateway URL by running these commands in the same shell:
export POD_NAME=$(kubectl get pods --namespace monitoring -l "app=prometheus,component=pushgateway" -o jsonpath="{.items[0].metadata.name}")
kubectl --namespace monitoring port-forward $POD_NAME 9091
For more information on running Prometheus, visit:
https://prometheus.io/
验证安装
- 查看相关相关资源情况
$kubectl get pod,svc,storageclasses,pvc,pv -n monitoring
NAME READY STATUS RESTARTS AGE
pod/monitor-prometheus-alertmanager-859d968679-pm859 2/2 Running 0 3m
pod/monitor-prometheus-kube-state-metrics-78b8d767dd-2f222 1/1 Running 0 3m
pod/monitor-prometheus-node-exporter-9h8wv 1/1 Running 0 3m
pod/monitor-prometheus-node-exporter-d6dfz 1/1 Running 0 3m
pod/monitor-prometheus-node-exporter-hbn7w 1/1 Running 0 3m
pod/monitor-prometheus-node-exporter-psvm7 1/1 Running 0 3m
pod/monitor-prometheus-node-exporter-rhwgr 1/1 Running 0 3m
pod/monitor-prometheus-pushgateway-5c587c85d5-glbbm 1/1 Running 0 3m
pod/monitor-prometheus-server-6ff6ff6bcf-pxdsb 2/2 Running 0 3m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/glusterfs-dynamic-monitor-prometheus-alertmanager ClusterIP 10.68.142.230 <none> 1/TCP 3m
service/glusterfs-dynamic-monitor-prometheus-server ClusterIP 10.68.45.230 <none> 1/TCP 3m
service/monitor-prometheus-alertmanager NodePort 10.68.159.44 <none> 80:39001/TCP 3m
service/monitor-prometheus-kube-state-metrics ClusterIP None <none> 80/TCP 3m
service/monitor-prometheus-node-exporter ClusterIP None <none> 9100/TCP 3m
service/monitor-prometheus-pushgateway ClusterIP 10.68.46.42 <none> 9091/TCP 3m
service/monitor-prometheus-server NodePort 10.68.43.210 <none> 80:39000/TCP 3m
NAME PROVISIONER AGE
storageclass.storage.k8s.io/glusterfs-storage kubernetes.io/glusterfs 15h
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
persistentvolumeclaim/monitor-prometheus-alertmanager Bound pvc-0d1588d0-b172-11e8-ac3b-0050569c7a12 5Gi RWO glusterfs-storage 3m
persistentvolumeclaim/monitor-prometheus-server Bound pvc-0d1624a7-b172-11e8-ac3b-0050569c7a12 20Gi RWO glusterfs-storage 3m
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
persistentvolume/pvc-0d1588d0-b172-11e8-ac3b-0050569c7a12 5Gi RWO Delete Bound monitoring/monitor-prometheus-alertmanager glusterfs-storage 3m
persistentvolume/pvc-0d1624a7-b172-11e8-ac3b-0050569c7a12 20Gi RWO Delete Bound monitoring/monitor-prometheus-server glusterfs-storage 3m
- 访问prometheus的web界面:
http://$NodeIP:39000
- 访问alertmanager的web界面:
http://$NodeIP:39001
部署Grafana
- 部署步骤参考prometheus的部署步骤
进入相关目录 #cd /etc/ansible/manifests/grafana
- 修改配置以启用持久化存储以及其他相关文件
values.yaml
persistence:
enabled: true
storageClassName: "glusterfs-storage"
accessModes:
- ReadWriteOnce
size: 10Gi
annotations: {}
subPath: ""
existingClaim:
grafana-settings.yaml
service:
type: NodePort
nodePort: 39002
adminUser: admin
adminPassword: admin
datasources:
datasources.yaml:
apiVersion: 1
datasources:
- name: MYDS_Prometheus
type: prometheus
#url: http:// + 集群里prometheus-server的服务名
#可以用 kubectl get svc --all-namespaces |grep prometheus-server查看
url: http://monitor-prometheus-server
access: proxy
isDefault: true
dashboardProviders:
dashboardproviders.yaml:
apiVersion: 1
providers:
- name: 'default'
orgId: 1
folder: ''
type: file
disableDeletion: false
editable: true
options:
path: /var/lib/grafana/dashboards
- helm方式安装grafana
$ helms install \ --name grafana \ --namespace monitoring \ -f grafana-settings.yaml \ grafana - 验证grafana安装情况
- 验证资源情况
$kubectl get pod,svc,storageclasses,pvc,pv -n monitoring
NAME READY STATUS RESTARTS AGE
pod/grafana-6779cbb56b-x8nxv 1/1 Running 0 1h
pod/monitor-prometheus-alertmanager-859d968679-pm859 2/2 Running 0 6h
pod/monitor-prometheus-kube-state-metrics-78b8d767dd-2f222 1/1 Running 0 6h
pod/monitor-prometheus-node-exporter-9h8wv 1/1 Running 0 6h
pod/monitor-prometheus-node-exporter-d6dfz 1/1 Running 0 6h
pod/monitor-prometheus-node-exporter-hbn7w 1/1 Running 0 6h
pod/monitor-prometheus-node-exporter-psvm7 1/1 Running 0 6h
pod/monitor-prometheus-node-exporter-rhwgr 1/1 Running 0 6h
pod/monitor-prometheus-pushgateway-5c587c85d5-glbbm 1/1 Running 0 6h
pod/monitor-prometheus-server-6ff6ff6bcf-pxdsb 2/2 Running 0 6h
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/glusterfs-dynamic-grafana ClusterIP 10.68.112.68 <none> 1/TCP 1h
service/glusterfs-dynamic-monitor-prometheus-alertmanager ClusterIP 10.68.142.230 <none> 1/TCP 6h
service/glusterfs-dynamic-monitor-prometheus-server ClusterIP 10.68.45.230 <none> 1/TCP 6h
service/grafana NodePort 10.68.84.138 <none> 80:39002/TCP 1h
service/monitor-prometheus-alertmanager NodePort 10.68.159.44 <none> 80:39001/TCP 6h
service/monitor-prometheus-kube-state-metrics ClusterIP None <none> 80/TCP 6h
service/monitor-prometheus-node-exporter ClusterIP None <none> 9100/TCP 6h
service/monitor-prometheus-pushgateway ClusterIP 10.68.46.42 <none> 9091/TCP 6h
service/monitor-prometheus-server NodePort 10.68.43.210 <none> 80:39000/TCP 6h
NAME PROVISIONER AGE
storageclass.storage.k8s.io/glusterfs-storage kubernetes.io/glusterfs 22h
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
persistentvolumeclaim/grafana Bound pvc-e5de3bd8-b1a1-11e8-ac3b-0050569c7a12 10Gi RWO glusterfs-storage 1h
persistentvolumeclaim/monitor-prometheus-alertmanager Bound pvc-0d1588d0-b172-11e8-ac3b-0050569c7a12 5Gi RWO glusterfs-storage 6h
persistentvolumeclaim/monitor-prometheus-server Bound pvc-0d1624a7-b172-11e8-ac3b-0050569c7a12 20Gi RWO glusterfs-storage 6h
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
persistentvolume/pvc-0d1588d0-b172-11e8-ac3b-0050569c7a12 5Gi RWO Delete Bound monitoring/monitor-prometheus-alertmanager glusterfs-storage 6h
persistentvolume/pvc-0d1624a7-b172-11e8-ac3b-0050569c7a12 20Gi RWO Delete Bound monitoring/monitor-prometheus-server glusterfs-storage 6h
persistentvolume/pvc-e5de3bd8-b1a1-11e8-ac3b-0050569c7a12 10Gi RWO Delete Bound monitoring/grafana glusterfs-storage 1h
- 访问grafana的web界面:
http://$NodeIP:39002
- 导入一些比较好用的模板
去grafana官网查找一些合适的kubernetes监控模板 官网地址:https://grafana.com/dashboards 觉得还不错的模板:https://grafana.com/dashboards/6417 自己用的其中一个模板文件: kubernetes-apps.json
{
"__inputs": [
{
"name": "DS_MYDS_PROMETHEUS",
"label": "MYDS_Prometheus",
"description": "",
"type": "datasource",
"pluginId": "prometheus",
"pluginName": "Prometheus"
}
],
"__requires": [
{
"type": "grafana",
"id": "grafana",
"name": "Grafana",
"version": "5.2.3"
},
{
"type": "panel",
"id": "graph",
"name": "Graph",
"version": "5.0.0"
},
{
"type": "datasource",
"id": "prometheus",
"name": "Prometheus",
"version": "5.0.0"
}
],
"annotations": {
"list": [
{
"builtIn": 1,
"datasource": "-- Grafana --",
"enable": true,
"hide": true,
"iconColor": "rgba(0, 211, 255, 1)",
"name": "Annotations & Alerts",
"type": "dashboard"
}
]
},
"editable": true,
"gnetId": null,
"graphTooltip": 0,
"id": null,
"iteration": 1536221609943,
"links": [],
"panels": [
{
"aliasColors": {},
"bars": false,
"dashLength": 10,
"dashes": false,
"datasource": "${DS_MYDS_PROMETHEUS}",
"fill": 1,
"gridPos": {
"h": 9,
"w": 12,
"x": 0,
"y": 0
},
"id": 4,
"legend": {
"alignAsTable": true,
"avg": true,
"current": true,
"max": true,
"min": true,
"show": true,
"total": false,
"values": true
},
"lines": true,
"linewidth": 1,
"links": [],
"nullPointMode": "null",
"percentage": false,
"pointradius": 5,
"points": false,
"renderer": "flot",
"seriesOverrides": [],
"spaceLength": 10,
"stack": false,
"steppedLine": false,
"targets": [
{
"expr": "avg(rate (container_cpu_usage_seconds_total{image!=\"\",container_name!=\"POD\",namespace=~'$namespace$',pod_name=~'$pod_name$',container_name=~'$container_name$'}[5m]))",
"format": "time_series",
"hide": false,
"instant": false,
"intervalFactor": 1,
"legendFormat": "CPU Usage",
"refId": "A"
}
],
"thresholds": [],
"timeFrom": null,
"timeShift": null,
"title": "CPU Usage",
"tooltip": {
"shared": true,
"sort": 0,
"value_type": "individual"
},
"type": "graph",
"xaxis": {
"buckets": null,
"mode": "time",
"name": null,
"show": true,
"values": []
},
"yaxes": [
{
"format": "short",
"label": null,
"logBase": 1,
"max": null,
"min": null,
"show": true
},
{
"format": "short",
"label": null,
"logBase": 1,
"max": null,
"min": null,
"show": true
}
],
"yaxis": {
"align": false,
"alignLevel": null
}
},
{
"aliasColors": {},
"bars": false,
"dashLength": 10,
"dashes": false,
"datasource": "${DS_MYDS_PROMETHEUS}",
"fill": 1,
"gridPos": {
"h": 9,
"w": 12,
"x": 12,
"y": 0
},
"id": 6,
"legend": {
"alignAsTable": true,
"avg": true,
"current": true,
"max": true,
"min": true,
"show": true,
"total": false,
"values": true
},
"lines": true,
"linewidth": 1,
"links": [],
"nullPointMode": "null",
"percentage": false,
"pointradius": 5,
"points": false,
"renderer": "flot",
"seriesOverrides": [],
"spaceLength": 10,
"stack": false,
"steppedLine": false,
"targets": [
{
"expr": "avg(container_memory_usage_bytes{image!=\"\",container_name!=\"POD\",namespace=~'$namespace$',pod_name=~'$pod_name$',container_name=~'$container_name$'})",
"format": "time_series",
"intervalFactor": 1,
"legendFormat": "MEM Usage",
"refId": "A"
}
],
"thresholds": [],
"timeFrom": null,
"timeShift": null,
"title": "MEM Usage",
"tooltip": {
"shared": true,
"sort": 0,
"value_type": "individual"
},
"type": "graph",
"xaxis": {
"buckets": null,
"mode": "time",
"name": null,
"show": true,
"values": []
},
"yaxes": [
{
"format": "short",
"label": null,
"logBase": 1,
"max": null,
"min": null,
"show": true
},
{
"format": "short",
"label": null,
"logBase": 1,
"max": null,
"min": null,
"show": true
}
],
"yaxis": {
"align": false,
"alignLevel": null
}
},
{
"aliasColors": {},
"bars": false,
"dashLength": 10,
"dashes": false,
"datasource": "${DS_MYDS_PROMETHEUS}",
"fill": 1,
"gridPos": {
"h": 9,
"w": 12,
"x": 0,
"y": 9
},
"id": 8,
"legend": {
"alignAsTable": true,
"avg": true,
"current": true,
"max": true,
"min": true,
"show": true,
"total": false,
"values": true
},
"lines": true,
"linewidth": 1,
"links": [],
"nullPointMode": "null",
"percentage": false,
"pointradius": 5,
"points": false,
"renderer": "flot",
"seriesOverrides": [],
"spaceLength": 10,
"stack": false,
"steppedLine": false,
"targets": [
{
"expr": "sum (rate (container_network_receive_bytes_total{image!=\"\",namespace=~'$namespace$',pod_name=~'$pod_name$'}[5m]))",
"format": "time_series",
"hide": false,
"intervalFactor": 1,
"legendFormat": "Network Input",
"refId": "A"
}
],
"thresholds": [],
"timeFrom": null,
"timeShift": null,
"title": "Network Input Bytes",
"tooltip": {
"shared": true,
"sort": 0,
"value_type": "individual"
},
"type": "graph",
"xaxis": {
"buckets": null,
"mode": "time",
"name": null,
"show": true,
"values": []
},
"yaxes": [
{
"format": "short",
"label": null,
"logBase": 1,
"max": null,
"min": null,
"show": true
},
{
"format": "short",
"label": null,
"logBase": 1,
"max": null,
"min": null,
"show": true
}
],
"yaxis": {
"align": false,
"alignLevel": null
}
},
{
"aliasColors": {},
"bars": false,
"dashLength": 10,
"dashes": false,
"datasource": "${DS_MYDS_PROMETHEUS}",
"fill": 1,
"gridPos": {
"h": 9,
"w": 12,
"x": 12,
"y": 9
},
"id": 10,
"legend": {
"alignAsTable": true,
"avg": true,
"current": true,
"max": true,
"min": true,
"show": true,
"total": false,
"values": true
},
"lines": true,
"linewidth": 1,
"links": [],
"nullPointMode": "null",
"percentage": false,
"pointradius": 5,
"points": false,
"renderer": "flot",
"seriesOverrides": [],
"spaceLength": 10,
"stack": false,
"steppedLine": false,
"targets": [
{
"expr": "sum (rate (container_network_transmit_bytes_total{image!=\"\",namespace=~'$namespace$',pod_name=~'$pod_name$'}[5m]))",
"format": "time_series",
"hide": false,
"intervalFactor": 1,
"legendFormat": "Network Output",
"refId": "A"
}
],
"thresholds": [],
"timeFrom": null,
"timeShift": null,
"title": "Network Output Bytes",
"tooltip": {
"shared": true,
"sort": 0,
"value_type": "individual"
},
"type": "graph",
"xaxis": {
"buckets": null,
"mode": "time",
"name": null,
"show": true,
"values": []
},
"yaxes": [
{
"format": "short",
"label": null,
"logBase": 1,
"max": null,
"min": null,
"show": true
},
{
"format": "short",
"label": null,
"logBase": 1,
"max": null,
"min": null,
"show": true
}
],
"yaxis": {
"align": false,
"alignLevel": null
}
},
{
"aliasColors": {},
"bars": false,
"dashLength": 10,
"dashes": false,
"datasource": "${DS_MYDS_PROMETHEUS}",
"fill": 1,
"gridPos": {
"h": 9,
"w": 12,
"x": 0,
"y": 18
},
"id": 12,
"legend": {
"alignAsTable": true,
"avg": true,
"current": true,
"max": true,
"min": true,
"show": true,
"total": false,
"values": true
},
"lines": true,
"linewidth": 1,
"links": [],
"nullPointMode": "null",
"percentage": false,
"pointradius": 5,
"points": false,
"renderer": "flot",
"seriesOverrides": [],
"spaceLength": 10,
"stack": false,
"steppedLine": false,
"targets": [
{
"expr": "sum (rate (container_network_receive_packets_total{image!=\"\",namespace=~'$namespace$',pod_name=~'$pod_name$'}[5m]))",
"format": "time_series",
"intervalFactor": 1,
"legendFormat": "Input Packets",
"refId": "A"
}
],
"thresholds": [],
"timeFrom": null,
"timeShift": null,
"title": "Network Input Packets",
"tooltip": {
"shared": true,
"sort": 0,
"value_type": "individual"
},
"type": "graph",
"xaxis": {
"buckets": null,
"mode": "time",
"name": null,
"show": true,
"values": []
},
"yaxes": [
{
"format": "short",
"label": null,
"logBase": 1,
"max": null,
"min": null,
"show": true
},
{
"format": "short",
"label": null,
"logBase": 1,
"max": null,
"min": null,
"show": true
}
],
"yaxis": {
"align": false,
"alignLevel": null
}
},
{
"aliasColors": {},
"bars": false,
"dashLength": 10,
"dashes": false,
"datasource": "${DS_MYDS_PROMETHEUS}",
"fill": 1,
"gridPos": {
"h": 9,
"w": 12,
"x": 12,
"y": 18
},
"id": 14,
"legend": {
"alignAsTable": true,
"avg": true,
"current": true,
"max": true,
"min": true,
"show": true,
"total": false,
"values": true
},
"lines": true,
"linewidth": 1,
"links": [],
"nullPointMode": "null",
"percentage": false,
"pointradius": 5,
"points": false,
"renderer": "flot",
"seriesOverrides": [],
"spaceLength": 10,
"stack": false,
"steppedLine": false,
"targets": [
{
"expr": "sum (rate (container_network_transmit_packets_total{image!=\"\",namespace=~'$namespace$',pod_name=~'$pod_name$'}[5m]))",
"format": "time_series",
"intervalFactor": 1,
"legendFormat": "Output Packets",
"refId": "A"
}
],
"thresholds": [],
"timeFrom": null,
"timeShift": null,
"title": "Network Output Packets",
"tooltip": {
"shared": true,
"sort": 0,
"value_type": "individual"
},
"type": "graph",
"xaxis": {
"buckets": null,
"mode": "time",
"name": null,
"show": true,
"values": []
},
"yaxes": [
{
"format": "short",
"label": null,
"logBase": 1,
"max": null,
"min": null,
"show": true
},
{
"format": "short",
"label": null,
"logBase": 1,
"max": null,
"min": null,
"show": true
}
],
"yaxis": {
"align": false,
"alignLevel": null
}
}
],
"schemaVersion": 16,
"style": "dark",
"tags": [],
"templating": {
"list": [
{
"allValue": null,
"current": {},
"datasource": "${DS_MYDS_PROMETHEUS}",
"hide": 0,
"includeAll": true,
"label": null,
"multi": false,
"name": "namespace",
"options": [],
"query": "label_values(container_memory_usage_bytes, namespace)",
"refresh": 1,
"regex": "",
"sort": 0,
"tagValuesQuery": "",
"tags": [],
"tagsQuery": "",
"type": "query",
"useTags": false
},
{
"allValue": null,
"current": {},
"datasource": "${DS_MYDS_PROMETHEUS}",
"hide": 0,
"includeAll": true,
"label": null,
"multi": false,
"name": "app_name",
"options": [],
"query": "label_values(container_memory_usage_bytes{namespace =~\"$namespace.*\"}, pod_name)",
"refresh": 1,
"regex": "/(.*)-.*/",
"sort": 0,
"tagValuesQuery": "",
"tags": [],
"tagsQuery": "",
"type": "query",
"useTags": false
},
{
"allValue": null,
"current": {},
"datasource": "${DS_MYDS_PROMETHEUS}",
"hide": 0,
"includeAll": true,
"label": null,
"multi": false,
"name": "pod_name",
"options": [],
"query": "label_values(container_memory_usage_bytes{pod_name =~\"$app_name.*\"}, pod_name)",
"refresh": 1,
"regex": "",
"sort": 0,
"tagValuesQuery": "",
"tags": [],
"tagsQuery": "",
"type": "query",
"useTags": false
},
{
"allValue": null,
"current": {},
"datasource": "${DS_MYDS_PROMETHEUS}",
"hide": 0,
"includeAll": true,
"label": null,
"multi": false,
"name": "container_name",
"options": [],
"query": "label_values(container_memory_usage_bytes{pod_name =~\"$pod_name.*\",container_name!=\"POD\"}, container_name)",
"refresh": 1,
"regex": "",
"sort": 0,
"tagValuesQuery": "",
"tags": [],
"tagsQuery": "",
"type": "query",
"useTags": false
}
]
},
"time": {
"from": "now-1h",
"to": "now"
},
"timepicker": {
"refresh_intervals": [
"5s",
"10s",
"30s",
"1m",
"5m",
"15m",
"30m",
"1h",
"2h",
"1d"
],
"time_options": [
"5m",
"15m",
"1h",
"6h",
"12h",
"24h",
"2d",
"7d",
"30d"
]
},
"timezone": "",
"title": "Kubernetes Apps",
"uid": "0xvoGCkmz",
"version": 1
}
管理操作
- 升级(修改配置):修改配置请在prom-settings.yaml, prom-alertsmanager.yaml等文件中进行,保存后执行如下操作:
# 修改prometheus
$ helms upgrade monitor -f prom-settings.yaml -f prom-alertsmanager.yaml -f prom-alertrules.yaml prometheus
# 修改grafana
$ helms upgrade grafana -f grafana-settings.yaml -f grafana-dashboards.yaml grafana
- 回退:具体可以参考helm help rollback文档
$ helms rollback monitor [REVISION]
- 删除
$ helms del monitor --purge
$ helms del grafana --purge
验证告警
- 修改
prom-alertsmanager.yaml文件中邮件告警为有效的配置内容,并使用 helms upgrade更新安装 - 查看
prom-alertrules.yaml文件,确认文件中设置了内存使用超过90%的告警规则 - 部署测试应用,并压力测试使其内存超过90%,看是否触发告警并发送告警邮件
# 创建deploy和service
$ kubectl run nginx1 --image=nginx --port=80 --expose --limits='cpu=500m,memory=4Mi'
# 增加负载(可用Ctrl + C 停止)
$ kubectl run --rm -it load-generator --image=busybox /bin/sh
Hit enter for command prompt
$ while true; do wget -q -O- http://nginx1; done;
# 等待约几分钟查看是否有告警
prometheus告警设置
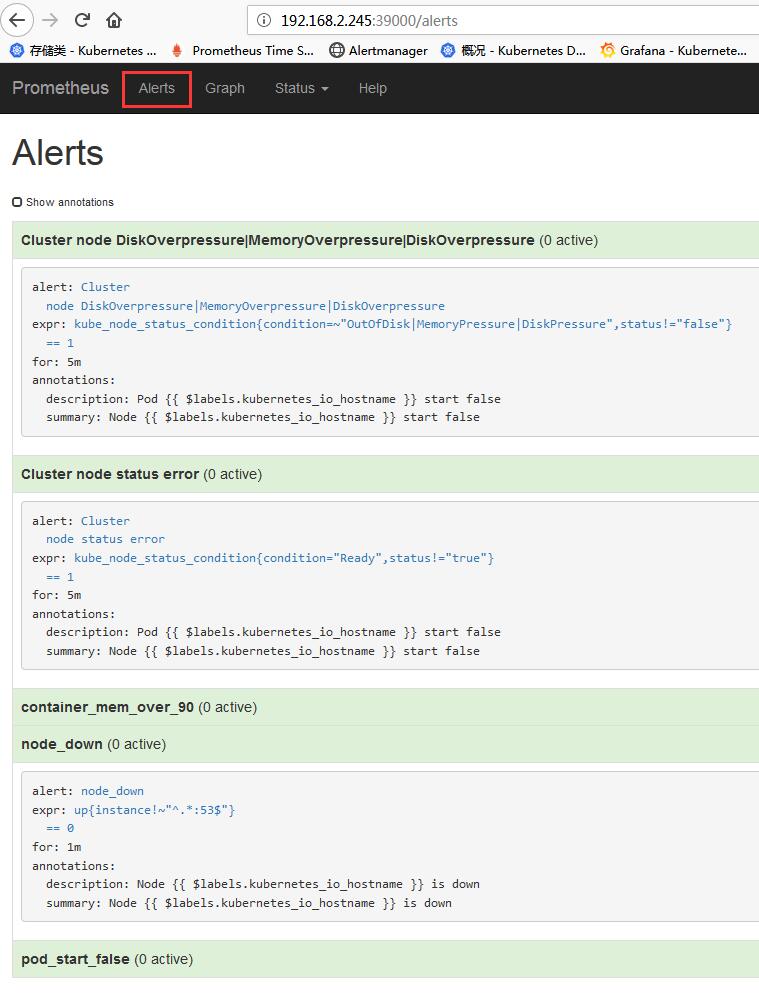
- 访问prometheus的web界面:
http://$NodeIP:39000
点击可查看具体告警规则配置
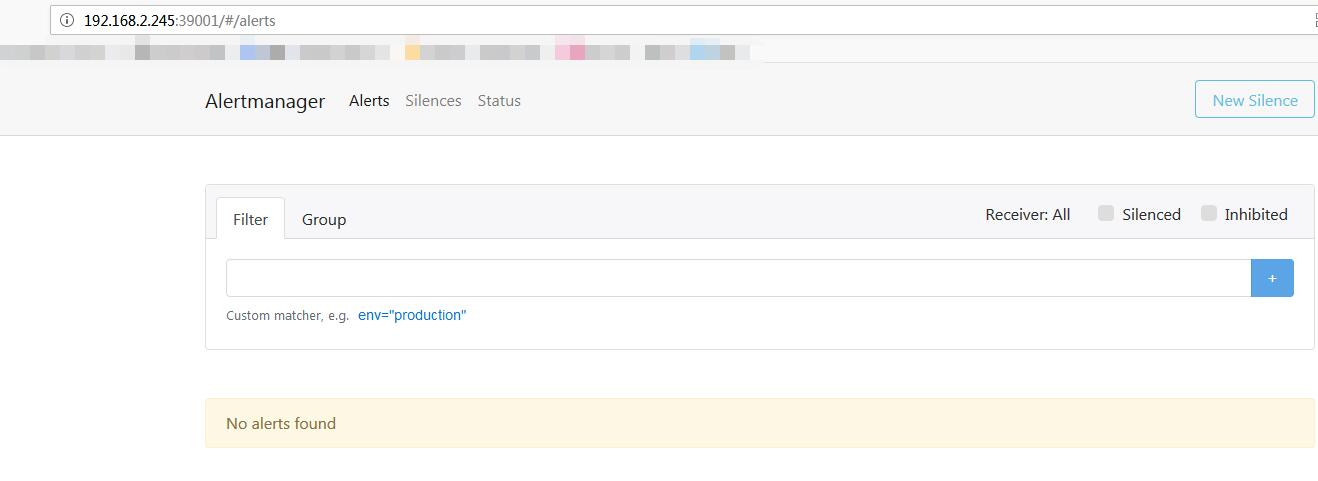
- 访问alertmanager的web界面:
http://$NodeIP:39001
如果已产生告警,可以在这里面查看到
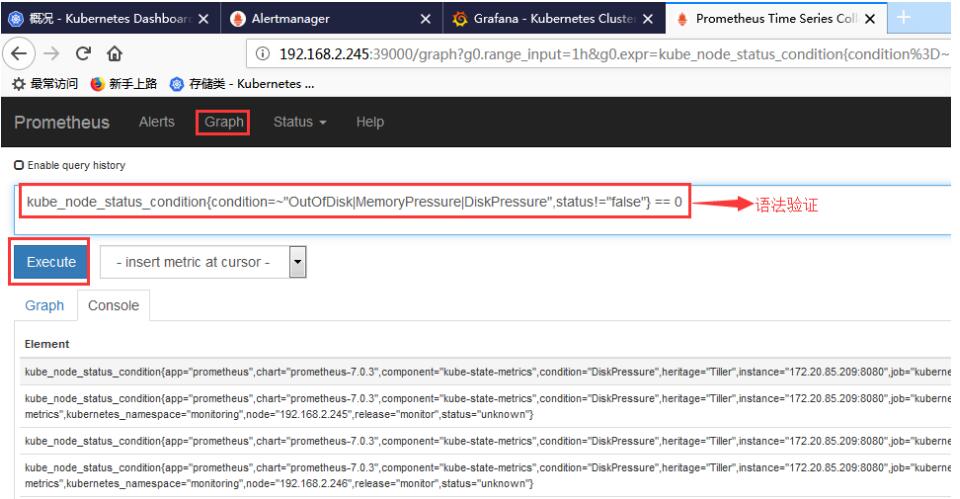
- 关于prometheus告警规则的编写,可以在以下图示位置进行规则语法和效果验证:
- 增加告警规则后生效方法:
$helms upgrade monitor -f prom-settings.yaml -f prom-alertsmanager.yaml -f prom-alertrules.yaml prometheus
- prometheus告警规则举例:
prom-alertrules.yaml
serverFiles:
alerts:
groups:
- name: k8s_alert_rules
rules:
# ALERT when container memory usage exceed 90%
- alert: container_mem_over_90
expr: (sum(container_memory_working_set_bytes{image!="",name=~"^k8s_.*", pod_name!=""}) by (pod_name)) / (sum (container_spec_memory_limit_bytes{image!="",name=~"^k8s_.*", pod_name!=""}) by (pod_name)) > 0.9 and (sum(container_memory_working_set_bytes{image!="",name=~"^k8s_.*", pod_name!=""}) by (pod_name)) / (sum (container_spec_memory_limit_bytes{image!="",name=~"^k8s_.*", pod_name!=""}) by (pod_name)) < 2
for: 2m
annotations:
summary: "'s memory usage alert"
description: "Memory Usage of Pod on has exceeded 90% for more than 2 minutes."
# ALERT when node is down
- alert: node_down
#expr: up == 0
expr: up{instance!~"^.*:53$"} == 0
for: 60s
annotations:
summary: "Node is down"
description: "Node is down"
# ALERT when pod 启动失败 !
- alert: pod_start_false
expr: kube_pod_status_phase{phase=~"Failed|Unknown"} == 1
for: 60s
annotations:
summary: "Pod start false"
description: "Pod start false"
# ALERT when 集群节点内存或磁盘资源短缺!
- alert: Cluster node DiskOverpressure|MemoryOverpressure|DiskOverpressure
expr: kube_node_status_condition{condition=~"OutOfDisk|MemoryPressure|DiskPressure",status!="false"} == 1
for: 300s
annotations:
summary: "Node start false"
description: "Pod start false"
# ALERT when 集群节点状态错误!
- alert: Cluster node status error
expr: kube_node_status_condition{condition="Ready",status!="true"} == 1
for: 300s
annotations:
summary: "Node start false"
description: "Pod start false"
- 其他监控规则参考:
存在执行失败的Job:
kube_job_status_failed{job="kubernetes-service-endpoints",k8s_app="kube-state-metrics"} == 1
集群中存在失败的PVC:
kube_persistentvolumeclaim_status_phase{phase="Failed"} == 1
- 最近30分钟内有Pod容器重启:
changes(kube_pod_container_status_restarts_total[30m]) > 0

对你有帮助,那就打赏一下吧




